PostGIS Performance Hacks
Regina Obe
Buy our books! https://postgis.us/page_buy_book
Latest books

|
 |

|
 |
What we'll cover
Part 1: Postgres is a workbench
- PostGIS family of extensions for working with spatial data
- ogr_fdw foreign data wrapper (FDW) and other FDWs, for pulling in spatial and non-spatial data.
- hstore for key/value data and using to convert OSM key value to json
CREATE EXTENSION IF NOT EXISTS postgis;Pull in spatial data with ogr_fdw
https://github.com/pramsey/pgsql-ogr-fdw
CREATE EXTENSION IF NOT EXISTS ogr_fdw;
CREATE SERVER svr_osm
FOREIGN DATA WRAPPER ogr_fdw
OPTIONS (
datasource '/vsicurl/http://postgis.us/downloads/foss4gna2025/dc.osm.pbf',
format 'OSM'
);
CREATE SCHEMA IF NOT EXISTS staging;
IMPORT FOREIGN SCHEMA ogr_all FROM SERVER svr_osm INTO staging;
Cascaded casting with Hstore
Use hstore extension to convert osm tags to jsonb using cascading casting
The casting :: operator is the casting operator and is short-hand for the SQL CAST(someobject AS somedatatype)
CREATE EXTENSION IF NOT EXISTS hstore;
CREATE TABLE dc_lines AS
SELECT osm_id::bigint, name, highway, other_tags::hstore::jsonb, geom
FROM staging.lines;
Your basic indexes
Regular spatial index
CREATE INDEX ix_dc_lines_geom_gist ON dc_lines USING gist(geom);Gin index for full text search and jsonb:
CREATE INDEX ix_dc_lines_other_tags_gin ON dc_pois USING gin(other_tags);Regular expression and ILIKE index support
Regular expression and ILIKE supporting index
CREATE EXTENSION IF NOT EXISTS pg_trgm;This will make your ILIKE and regular expression searches be able to use an index
CREATE INDEX ix_dc_pois_name ON dc_pois USING gin(name gin_trgm_ops);ILIKE query
EXPLAIN (analyze,verbose) SELECT name FROM dc_pois WHERE name ILIKE '%doc%';Bitmap Heap Scan on foss4gna_2025.dc_pois (cost=12.82..16.83 rows=1 width=19)
(actual time=0.069..0.071 rows=1.00 loops=1)
Output: name
Recheck Cond: ((dc_pois.name)::text ~~* '%doc%'::text)
Heap Blocks: exact=1
Buffers: shared hit=4
-> Bitmap Index Scan on ix_dc_pois_name_trgm (cost=0.00..12.82 rows=1 width=0)
(actual time=0.031..0.032 rows=1.00 loops=1)
Index Cond: ((dc_pois.name)::text ~~* '%doc%'::text)
Index Searches: 1
Buffers: shared hit=3
Planning:
Buffers: shared hit=1
Planning Time: 0.459 ms
Execution Time: 0.120 ms
Regex query
EXPLAIN (analyze,verbose) SELECT name FROM dc_pois WHERE name ~ '^[0-9]';Bitmap Heap Scan on foss4gna_2025.dc_pois (cost=95.58..1271.24 rows=863 width=19)
(actual time=0.855..2.938 rows=874.00 loops=1)
Output: name
Recheck Cond: ((dc_pois.name)::text ~ '^[0-9]'::text)
Rows Removed by Index Recheck: 337
Heap Blocks: exact=249
Buffers: shared hit=270
-> Bitmap Index Scan on ix_dc_pois_name_trgm
(cost=0.00..95.37 rows=863 width=0)
(actual time=0.721..0.722 rows=1211.00 loops=1)
Index Cond: ((dc_pois.name)::text ~ '^[0-9]'::text)
Index Searches: 1
Buffers: shared hit=21
Planning:
Buffers: shared hit=1
Planning Time: 0.433 ms
Execution Time: 3.102 ms
Compound Indexes: Extensions you'll need
Have more than one column in index.
-- for combining spatial index with btree
CREATE EXTENSION IF NOT EXISTS btree_gist;
-- for combining full-text, jsonb index with btree
CREATE EXTENSION IF NOT EXISTS btree_gin;Creating compound index
If you query spatial often in conjunction with a non-spatial column, create a btree_gist compound index instead.
DROP INDEX IF EXISTS ix_dc_lines_geom_gist;
CREATE INDEX ix_dc_lines_geom_highway_gist ON dc_lines USING gist(geom, highway);
Just filtering by first column (geom)
EXPLAIN (analyze, verbose, buffers) SELECT name, geom, highway
FROM dc_lines
WHERE ST_Intersects(geom,
ST_MakeEnvelope(-77.06147, 38.8714,-77.0514, 38.8814, 4326) );Bitmap Heap Scan on foss4gna_2025.dc_lines (cost=9.46..2374.87 rows=152 width=168)
(actual time=0.271..1.319 rows=216.00 loops=1)
Output: name, geom, highway
Filter: st_intersects(dc_lines.geom, '0103000020E610000001000000050..'::geometry)
Rows Removed by Filter: 5
Heap Blocks: exact=60
Buffers: shared hit=78
-> Bitmap Index Scan on ix_dc_lines_geom_highway_gist (cost=0.00..9.42 rows=152 width=0)
(actual time=0.179..0.179 rows=221.00 loops=1)
Index Cond: (dc_lines.geom && '0103000020E610000..'::geometry)
Index Searches: 1
Buffers: shared hit=15
Planning Time: 0.380 ms
Execution Time: 1.397 ms
Second column only filter (highway)
EXPLAIN (analyze, verbose, buffers) SELECT count(*), highway
FROM dc_lines
WHERE highway IN('residential', 'secondary')
GROUP BY highway
ORDER BY highway; QUERY PLAN
--------------------------------------------------------------------------------------------------------
Sort (cost=2320.12..2320.18 rows=25 width=16) (actual time=37.819..37.824 rows=2.00 loops=1)
Output: (count(*)), highway
Sort Key: dc_lines.highway
Sort Method: quicksort Memory: 25kB
Buffers: shared hit=2108
-> HashAggregate (cost=2319.29..2319.54 rows=25 width=16)
(actual time=37.730..37.735 rows=2.00 loops=1)
Output: count(*), highway
Group Key: dc_lines.highway
Batches: 1 Memory Usage: 32kB
Buffers: shared hit=2105
-> Bitmap Heap Scan on foss4gna_2025.dc_lines (cost=342.19..2284.68 rows=6920 width=8)
(actual time=24.920..34.233 rows=6932.00 loops=1)
Output: osm_id, name, highway, other_tags, geom
Recheck Cond: ((dc_lines.highway)::text = ANY ('{residential,secondary}'::text[]))
Heap Blocks: exact=1196
Buffers: shared hit=2105
-> Bitmap Index Scan on ix_dc_lines_geom_highway_gist (cost=0.00..340.45 rows=6920 width=0)
(actual time=24.583..24.585 rows=6932.00 loops=1)
Index Cond: ((dc_lines.highway)::text = ANY ('{residential,secondary}'::text[]))
Index Searches: 2
Buffers: shared hit=909
Planning:
Buffers: shared hit=184
Planning Time: 1.972 ms
Execution Time: 43.072 ms
(23 rows)
Best if use both
Most efficient when querying both columns
EXPLAIN (analyze, verbose, buffers) SELECT name, geom, highway
FROM dc_lines
WHERE highway IN('residential', 'secondary', 'tertiary')
AND ST_Intersects(geom,
ST_MakeEnvelope(-77.06147, 38.8714,-77.0514, 38.8814, 4326) ); Bitmap Heap Scan on foss4gna_2025.dc_lines (cost=13.11..433.23 rows=26 width=168)
(actual time=0.490..0.552 rows=9.00 loops=1)
Output: name, geom, highway
Recheck Cond: ((dc_lines.highway)::text = ANY ('{residential,secondary,tertiary}'::text[]))
Filter: st_intersects(dc_lines.geom, '0103000020E6100000010...' Heap Blocks: exact=5
Buffers: shared hit=29
-> Bitmap Index Scan on ix_dc_lines_geom_highway_gist
(cost=0.00..13.10 rows=26 width=0)
(actual time=0.406..0.406 rows=9.00 loops=1)
Index Cond: ((dc_lines.geom && '0103000020...'::geometry)
AND ((dc_lines.highway)::text = ANY ('{residential,secondary,tertiary}'::text[])))
Index Searches: 3
Buffers: shared hit=24
Planning Time: 0.514 ms
Execution Time: 0.627 ms
Functional indexes
Indexes based on functional expressions. Saves disk space, but requires you use the functional expression in your queries for index to kick in.
CREATE INDEX ix_dc_lines_geom_geog_gist ON dc_lines USING gist ( (geom::geography) );
-- transform from nyc state plane meters to geography
CREATE INDEX ix_nyc_streets_geom_geog_gist ON nyc_streets
USING gist ( ( ST_Transform(geom,4326)::geography ) );SELECT name, geom
FROM dc_lines
-- within 1000 meters
WHERE ST_DWithin( geom::geography, ST_Point(-77.024,38.883,4326)::geography, 1000);Partial indexes
Makes your indexes smaller by indexing a subset of the data
-- OMG - this is a compound (gist btree monster) partial functional index
CREATE INDEX ix_dc_lines_geom_geog_gist_highways ON dc_lines
USING gist ( (geom::geography), highway )
WHERE highway IS NOT NULL;Common Table Expressions (CTE)
Useful for breaking your query into logical chunks and/or as a planner guard.
WITH
-- OFFSET 0 planner guard hack, works in all versions of Postgres
pri AS
( SELECT name, geom
FROM dc_lines
WHERE highway = 'primary' AND name > ''
AND ST_Intersects(geom, ST_Expand(ST_Point(-77.024, 38.883, 4326), 0.05) )
ORDER BY name OFFSET 0
)
-- PG12+ planner guard, note there is a NOT MATERIALIZED option too
, traf AS MATERIALIZED ( SELECT osm_id::text AS name, geom
FROM dc_pois
WHERE highway = 'traffic_signals'
)
-- breaking query into manageable chunks
, tn AS (SELECT osm_id, tag_name, tag_value, the_geom AS geom
FROM osm_nodes
WHERE tag_name > '')
SELECT 'pri' AS type, pri.name, ST_Union(tn.geom) AS mp_geom
FROM pri INNER JOIN tn ON ST_Intersects(pri.geom, tn.geom)
GROUP BY pri.name
UNION ALL
SELECT 'traf' As type , traf.name, ST_Union(tn.geom) AS mp_geom
FROM traf
INNER JOIN tn ON ST_DWithin(traf.geom, tn.geom, 0.05)
GROUP BY traf.name;Regular Views
Compartimentalize commonly used constructs in a view
CREATE OR REPLACE VIEW vw_highways AS
SELECT *, geom::geography AS geog
FROM dc_lines
WHERE highway IS NOT NULL;No need to remember to cast your geom to geography anymore just query the view
EXPLAIN (analyze) SELECT *
FROM vw_highways
WHERE ST_DWithin( geog, ST_Point(-77.024,38.883,4326)::geography, 1000)
AND highway IN('residential');Index Scan using ix_dc_lines_geom_geog_gist_highways on dc_lines (cost=0.40..20.93 rows=1 width=363)
(actual time=0.264..4.732 rows=39.00 loops=1)
Index Cond: (((geom)::geography && _st_expand('010100..'::geography, '1000'::double precision))
AND ((highway)::text = 'residential'::text))
Filter: st_dwithin((geom)::geography, '01010..::geography, '1000'::double precision, true)
Rows Removed by Filter: 34
Index Searches: 1
Buffers: shared hit=139
Planning Time: 0.406 ms
Execution Time: 4.795 ms
Materialized Views
Store heavy compute results
LIMITATIONS - has to be dropped and recreated if you change the definition. They don't automatically refresh themselves yet - Keeping materialized view updated approaches
CREATE MATERIALIZED VIEW vw_mat_nyc_boros_geog AS
SELECT boroname, ST_Transform(
ST_Union(
ST_ReducePrecision(ST_MakeValid(geom),0.005)
), 4326
)::geography(MULTIPOLYGON,4326) AS geog
FROM nyc_neighborhoods
GROUP BY boroname;
CREATE UNIQUE INDEX ux_vw_mat_nyc_boros_geog
ON vw_mat_nyc_boros_geog(boroname);
CREATE INDEX ix_vw_mat_nyc_boros_geog_gist ON vw_mat_nyc_boros_geog USING gist(geog);Refreshing materialized views
Make sure you have a unique index so you can refresh concurrently
REFRESH MATERIALIZED VIEW CONCURRENTLY vw_mat_nyc_boros_geog;Computed Columns
Two types and can only be based on IMMUTABLE expressions. Not that useful yet for spatial queries.
- STORED, that is the only type that has existed prior to PG 18. Data is physically stored.
- VIRTUAL, new in PG18 data is computed at read time, kind of like a column in a view, but can only use built-in functions, sorry no PostGIS functions.
Limitation Output of the column has to be a PostgreSQL included type, so NO you can't have columns defined as type geography here, but you can use PostGIS functions that return scalars like area/length etc, if STORED.
ALTER TABLE dc_lines
ADD COLUMN length_m numeric GENERATED ALWAYS AS ( ST_Length(geom::geography) ) STORED;
-- and you can add an index on a generated column
CREATE INDEX ix_dc_lines_length_m ON dc_lines(length_m);PostgreSQL system settings
-- total processes allowed for postgresql use
ALTER SYSTEM set max_worker_processes=12;
-- set to max number of processes for parallel work
ALTER SYSTEM set max_parallel_workers=4;
ALTER SYSTEM set work_mem='250MB';
-- memory used for caching data shareable
ALTER SYSTEM set shared_buffers='10GB';
-- you shouldn't need to fiddle with this
-- but lower if you want to encourage parallel query
set parallel_tuple_cost=0.01;
-- has to be at most max_parallel_workers
set max_parallel_workers_per_gather=2;
PostgreSQL planner settings
SELECT name, setting , category
FROM pg_settings
WHERE category ILIKE 'Query Tuning%'
ORDER BY name;This doesn't use an index
This particular query doesn't use an index, is it because it can't or the planner thinks it's better to scan the table?
EXPLAIN (analyze,verbose) SELECT name FROM dc_pois WHERE name ~ 'A[0-9]';Seq Scan on foss4gna_2025.dc_pois (cost=0.00..1976.00 rows=1 width=19) (actual time=25.953..25.955 rows=0.00 loops=1) Output: name Filter: ((dc_pois.name)::text ~ 'A[0-9]'::text) Rows Removed by Filter: 60800 Buffers: shared hit=1216 Planning: Buffers: shared hit=1 Planning Time: 0.448 ms Execution Time: 25.998 ms
Screw with the planner
What if you tell the planner to avoid sequential scans, then it will try to use an index that can be used.
set enable_seqscan=false;
EXPLAIN (analyze,verbose) SELECT name FROM dc_pois WHERE name ~ 'A[0-9]';Bitmap Heap Scan on foss4gna_2025.dc_pois
(cost=48449.79..48453.80 rows=1 width=19)
(actual time=24.583..24.585 rows=0.00 loops=1)
Output: name
Recheck Cond: ((dc_pois.name)::text ~ 'A[0-9]'::text)
Rows Removed by Index Recheck: 9166
Heap Blocks: exact=764
Buffers: shared hit=878
-> Bitmap Index Scan on ix_dc_pois_name_trgm
(cost=0.00..48449.79 rows=1 width=0)
(actual time=11.290..11.290 rows=9166.00 loops=1)
Index Cond: ((dc_pois.name)::text ~ 'A[0-9]'::text)
Index Searches: 1
Buffers: shared hit=114
Planning:
Buffers: shared hit=1
Planning Time: 0.444 ms
Execution Time: 24.649 ms
Make geometries smaller
- The bigger your bounding box, the more rechecks need to be done against index results - ST_Subdivide, ST_SquareGrid, ST_HexagonGrid
- The more points your geometries have, the slower processes like intersects and contains are to do. ST_Simplify*
ST_HexagonGrid
Hexagon Grids and Square Grids work against bounding box, and units are in units of spatial ref sys. Make sure to filter out those that don't intersect and clip those that overlap
-- units in NY state plane meters
SELECT n.boroname, n.name,
CASE WHEN ST_Covers(n.geom, hg.geom)
THEN hg.geom ELSE ST_Intersection(n.geom,hg.geom)
END AS geom,
hg.i, hg.j
FROM nyc_neighborhoods AS n
INNER JOIN LATERAL ST_HexagonGrid(500, n.geom) AS hg
ON ST_Intersects(n.geom, hg.geom)
WHERE n.boroname = 'The Bronx';
With clipping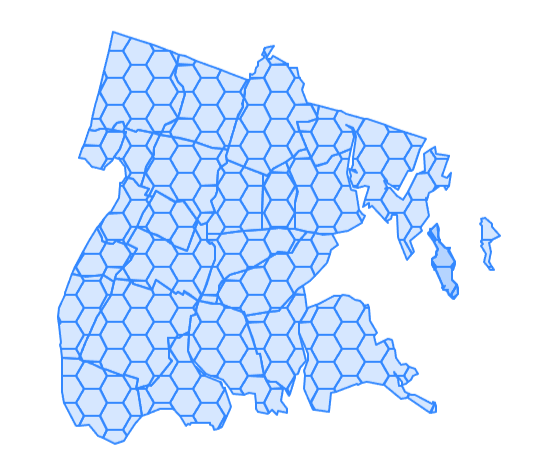 |
No ST_Covers clipping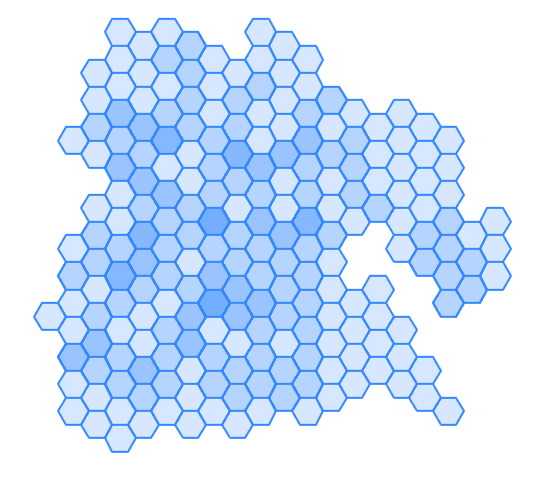 |
Leveraging geometry functions for geography
Many geometry functions assume you are working in an area/measurement preserving spatial ref sys for optimal results
- ST_Segmentize for geography is a super weapon to leverage geometry functions.
- _ST_BestSRID is another (not documented)
ST_Subdivide on geography
Before you apply subdivide on degree geometries, segmentize them in geography first. ST_Segmentize units for geography are in meters.
Break state edges so each edge no longer than 10000 meters, then chop up state so no piece has more than 500 vertices
--- from 52 rows to 4242 rows
CREATE TABLE chopped_states AS SELECT s.stusps, sd.geom::geography AS geog
FROM tiger.state AS s
CROSS JOIN LATERAL
ST_Subdivide(
ST_Segmentize(s.the_geom::geography, 10000)::geometry, 500
) AS sd(geom);
Part 2: Postgres is a workbench
- http: https://github.com/pramsey/pgsql-http
- open-ai: https://github.com/pramsey/pgsql-openai not packaged as an extension, just an sql file
- PostGIS: https://postgis.net
Open-ai script, it's misnamed
http extension is available from many packagers or you can build yourself - https://github.com/pramsey/pgsql-http
works with ollama local also - https://ollama.com
CREATE EXTENSION IF NOT EXISTS http;
-- run this script https://github.com/pramsey/pgsql-openai/blob/main/openai--1.0.sql
AI: Setup
Using local ollama models
SET openai.api_uri = 'http://127.0.0.1:11434/v1/';
SET openai.api_key = 'none';
SELECT * FROM openai.models();
id | object | created | owned_by ----------------+--------+---------------------+---------- gemma3:4b | model | 2025-10-17 00:59:31 | library phi4:latest | model | 2025-10-17 00:58:59 | library gpt-oss:latest | model | 2025-10-17 00:55:50 | library (3 rows)
Postgres, AI, and PostGIS in Action
SET openai.prompt_model = 'gpt-oss:latest';
-- 1.7.0 syntax, use http_set_curlopt function for older versions
SET http.curlopt_timeout = '1000';
-- (took 2 minutes on my pc)
CREATE TEMP TABLE tmp_ai_data AS
SELECT openai.prompt('Provide answer in json format enclosed by
--start json-- --end json--'
, 'Return a list of restaurants in the Reston, VA, USA area
, with the following fields:
name
longitude
latitude
most_popular_items (as array with fields: name, price)') AS data;Postgres, AI, PostGIS in Action
SELECT data FROM tmp_ai_data;
--start json--
[
{
"name": "Bodega",
"longitude": -77.3732,
"latitude": 38.9870,
"most_popular_items": [
{ "name": "Chicken Shawarma", "price": "$8.99" },
{ "name": "Burrito", "price": "$7.99" },
{ "name": "Tacos", "price": "$6.99" }
]
},
{
"name": "Southeast Asian Bistro",
"longitude": -77.3800,
"latitude": 38.9835,
"most_popular_items": [
{ "name": "Pad Thai", "price": "$12.99" },
{ "name": "Kung Pao Chicken", "price": "$13.49" },
{ "name": "Dumplings", "price": "$10.99" }
]
},
:
-- end json --
Cascading function laterals
Massage into a table structure
CREATE TABLE hot_menu AS
SELECT je->>'name' AS restaurant,
me->>'name' AS food_name,
replace(me->>'price', '$','')::numeric AS price,
ST_Point((je->>'longitude')::numeric,
(je->>'latitude')::numeric,4326
)::geography AS geog
FROM ai_data AS aid
-- cross join lateral, to expand each array as an element
, jsonb_array_elements(
-- substring function with regular expression, to parse out the json data
substring(aid.data, '--start json--(.*)--end json--')::jsonb
) AS je
-- expand the array menu from each restaurant
, jsonb_array_elements(
je->'most_popular_items'
) AS me;Visual in pgAdmin
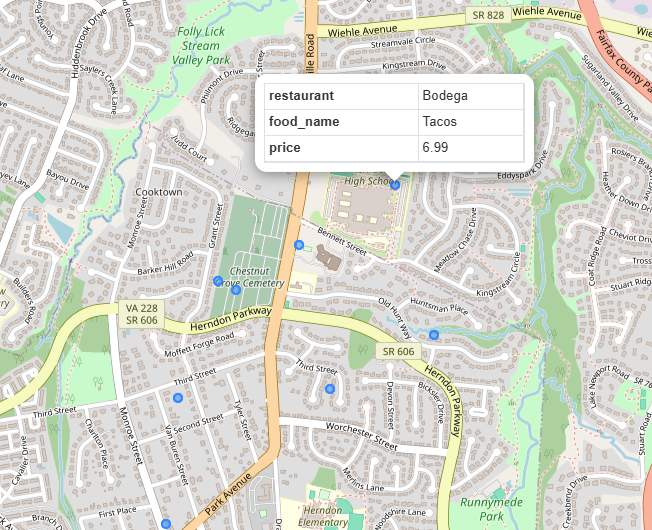
Menu items
Top 5 most expensive dishes from the popular set
SELECT restaurant, food_name, price
FROM hot_menu
ORDER BY price DESC LIMIT 5;restaurant | food_name | price ------------------------+------------------+------- The Dandelion | Burger | 14.99 Ramen House | Tonkotsu Ramen | 13.99 The Dandelion | Fish & Chips | 13.99 Bok | Bulgogi | 13.99 Southeast Asian Bistro | Kung Pao Chicken | 13.49 (5 rows)